
I just spent a week of vacation in Italy. One of my good friends from college was getting married, and I didn’t want to miss his wedding. It was a good time for Kelly (my wife) and I to also take a week of vacation prior to the wedding. We love Italy, and a wedding was a good excuse for us to go there again.
During vacations (and during long flights) I like to read a good book. During this trip, I had loaded Weapons of Math Destruction by Cathy O’Neil on my Kindle. This was a fantastic read! When reading a book, I sometimes pause and read a passage to my wife. I know it’s a good book when she is intrigued by it and we can discuss that passage.
The main concept throughout the whole book is the negative side-effect of big data models and AI on certain parts of our society. The author calls the big data or AI models that have those negative side-effects ‘Weapons of Math Destruction’ (WMD for short). She does a really good job in talking through the actual cause and effect relationship behind these WMDs, and giving very personable examples in each of the different chapters.
When I finished the book I spent some time thinking about what I learned. And the more I thought about it, the more I actually wanted to share what I learned and provoke a discussion.
Does this rising tide lift all boats?
I love the expression ‘a rising tide lifts all boats’. If you think about ships on the sea, or even on a river, if the water level rises, all ships move upwards with the rising tide. I would love for this to be true for our society as well, and it certainly is in some cases. Literacy rates are going up all around the world, child mortality is declining and overall, less people are living in extreme poverty.
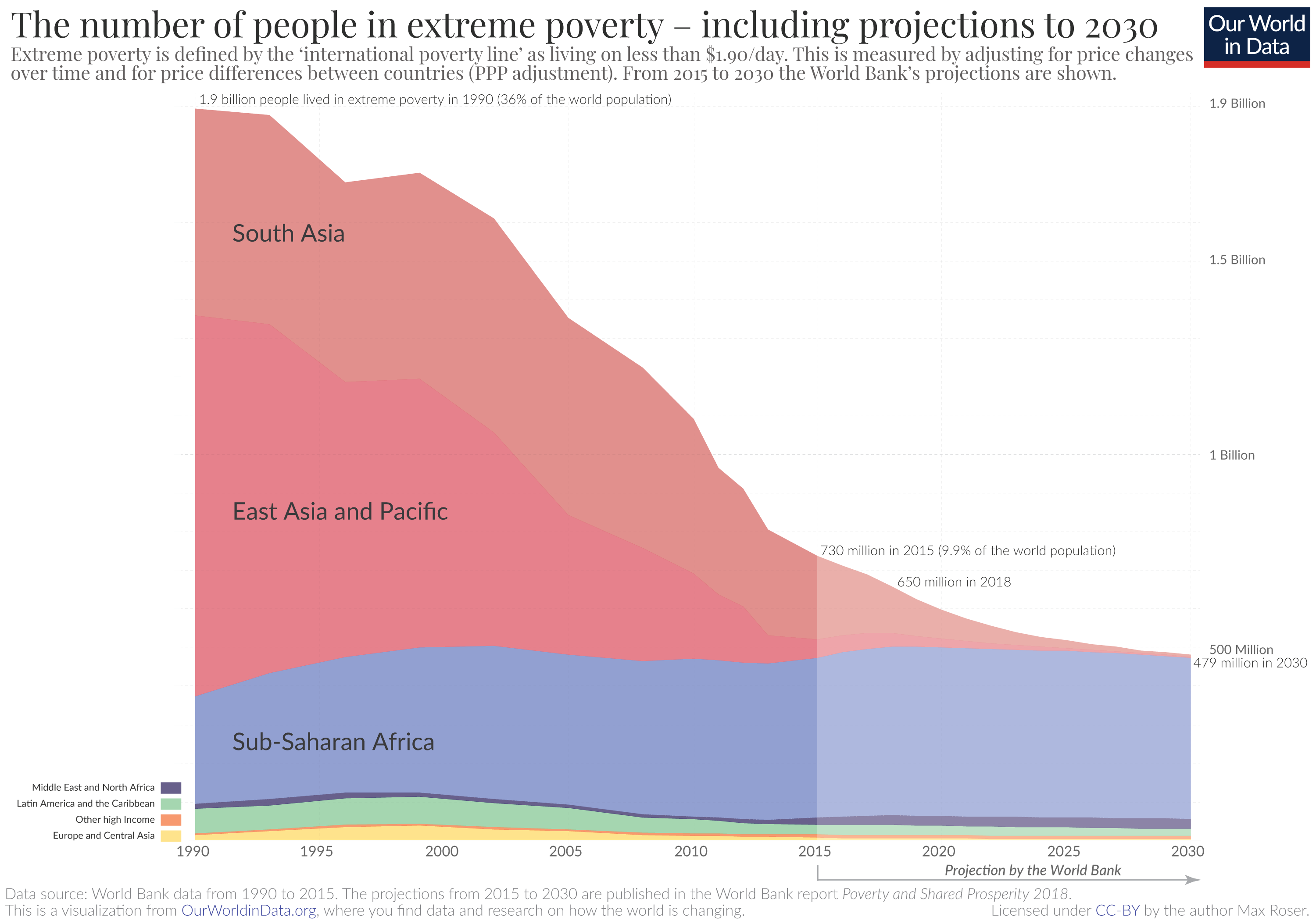{kind=link}
However, the author of this book makes a couple of excellent cases where this is not true. One very specific example that struck me personally is the optimization of staff hours in retail stores and specifically the phenomenon of ‘clopening’. Clopening is a term created for when an employee of a retail closes the store one evening and opens that same store the day after, with limited actual time of work.
This example was relevant for my own personal situation. During my student years, I worked as a waiter for about 7 years. I made less on an hourly basis than my friends did working 9 to 5 desk jobs during summers, but I had the ability to make up for it with working extra hours (not by tips however. I am from Belgium, where tipping your waiter isn’t as big as in the US. I was happy with a 2% average tip at the end of the day).
All large retailers by now use scheduling software to plan employee hours. In my naivety, I would expect a computer program to have a simple control loop that avoids clopenings from happening. At least, from having them happen frequently. But clopenings happen frequently, and when a scheduling algorithm is optimized for other metrics, this weird side effect creeps in. Even worse, the author mentions cases where low-wage workers’ hours are optimized for them to stay below the ‘eligible for medical insurance’-mark. Just imagine having to close a store at 11PM, being there the next day at 7AM for the opening but not working enough hours during the week to be eligible for medical insurance.
I understand from a business owner perspective that personnel cost is a major cost for a business. And as a business owner and shareholder, your primary goal is to optimize for business results. The ethical question you should ask yourself is whether this business result is gained by outsmarting your competition or by selling more, or rather if it is gained by profiting from paying your minimum-wage employees as little as possible.
And if this is the case, I would argue that the rising isn’t lifting all boats at all. If a retail employee has to suffer both clopenings and working very irregular hours there is something wrong with your scheduling algorithm. And you could indeed call this a ‘weapon of math destruction’ optimized for a poor metric.
How can someone get out of a reinforcing downward spiral?
Data is the new oil. The more data a business has, the more valuable that business can become. If you want to train a machine learning algorithm, you need as much data as you can get. Having the right data, and much of that, will enable you to make better predictions, and tailor your products and its pricing to the customers you are serving.
However, not all data is created equally and not all data has the same value. There is already a legislative framework that prohibits certain data to be part of a decision. A loan application shouldn’t be influenced by matters such as race or gender. The problem with data is however, that some of those prohibited matters can be learned from the data.
The book has a couple of great examples about the usage of a ZIP code. ZIP codes can for instance be correlated to crime rates, to default rates on mortgages and to college graduation rates. As a mortgage provider, it only makes sense for you to use this metric to optimize your business. If people living in a certain neighborhood are more likely to default on their mortgage, it might make sense for you to ask for a premium to that population.
This logic creates a problem. This problem boils down to creating a downwards spiral that is hard to impossible to get out of. Sticking with the mortgage example, people likely live in a neighborhood because of their social background. This background doesn’t only influence their living location, but also their school choices and often job choices. If this impacts those people’s mortgage rate, and makes their mortgage more expensive, it is harder for them to first make their payments and secondly to potentially move out of that neighborhood to a ‘better’ area. If it’s harder for a person to make mortgage payments, they are more likely to miss payments. This in turn will reinforce the machine learning algorithm with more data that a certain population misses payments. So, even more people of your neighborhood will get higher interest rates. And this spiral is hard to impossible to get out of.
It’s even harder to break out of this spiral if you consider that your zip code can influence not only your mortgage, but also your car insurance rate (apparently even more than drunk driving history) and even your acceptance rates in colleges and universities. The book has a number of examples in those area, that sound reasonable from a certain perspective (a business wanting to make profit), but in the same time make you think about how a person could get out of this spiral.
There is a silver lining, and we should pay close attention to how we use AI models.
I am an optimist. I believe that big data and AI will have a positive impact on society. To reach this positive impact, we should pay close attention to how we use our models.
Let’s take the previous example of the mortgage model trained on ZIP code data. In the example, we discussed that the data tells us that people from certain ZIP codes are more likely to default on their mortgage. Instead of using this data and this model to influence people’s mortgage rates, why don’t we use it to offer them with better protection? This protection could be as simple as offering those people with courses in financial literacy and regular follow-up to check up on their finances, or even offering them an additional insurance that would protect them.
That’s one place where the book in my point of view could have been a bit more prescriptive. There are only a couple of example of positive models being used, or models being used differently to have a positive impact. The book felt very negative in that regard, showing a lot of negative example, with only a couple of empowering positive impacts. As an optimist, I took those couple of positive examples at heart and want to make sure that we implement the technology the right way to have a positive impact.
Conclusion
The main conclusion here is I highly recommendation you to read this book and form your own opinions. It certainly has given me a different perspective, and I hope it will do the same for you.
From a practical lens, I got a couple of learnings from this book. One is to consider multiple perspectives when thinking about or even designing an AI algorithm. The second is to make sure that the model doesn’t reinforce itself and creates downwards spirals. Finally, and that’s the most positive learning, is to consider how the technology can be used to create WIN-WIN situations, that can benefit all stakeholders.