
I spent some time last week running sample apps using LangChain to interact with Azure OpenAI. Most (if not all) of the examples connect to OpenAI natively, and not to Azure OpenAI. It took a little bit of tinkering on my end to get LangChain to connect to Azure OpenAI; so, I decided to write down my thoughts about you can use LangChain to connect to Azure OpenAI.
LangChain is a framework designed to simplify the creation of applications using large language models (LLMs). It is a language model integration framework that can be used for document analysis and summarization, chatbots, and code analysis. It allows you to build more complicated interactions with a language model without having to write a lot of the prompt engineering and orchestration. You can learn more about LangChain by visiting their official website.
What you need from Azure OpenAI
I’ll assume if you’re reading this, that you already have access to Azure OpenAI. If you don’t have access already, please refer to the Azure documentation for how to get access.
We’ll need to get the following information from the Azure OpenAI service:
OPENAI_API_BASE = "https://nillsf-openai.openai.azure.com/"
OPENAI_API_KEY = "xxx"
OPENAI_API_TYPE = "azure"
OPENAI_DEPLOYMENT_NAME = "nillsf-embeddings"
OPENAI_DEPLOYMENT_VERSION = "2"
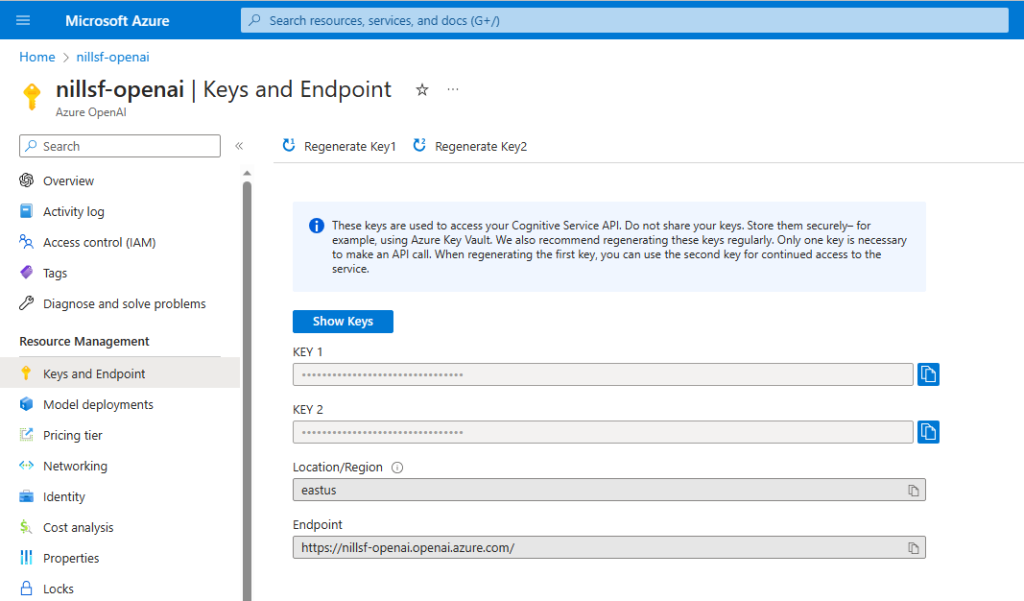
OPENAI_MODEL_NAME="text-embedding-ada-002"The first two items you can get from the Azure portal. Open your OpenAI resource, and select “Keys and Endpoint” in the left-hand navigation. There you’ll find your endpoint and the two keys. Grab one of the keys, you don’t need both.
(side-note: you can optionally configure Azure OpenAI and LangChain to leverage AAD authentication. For this post, we’ll assume you’ll use key based authentication.)
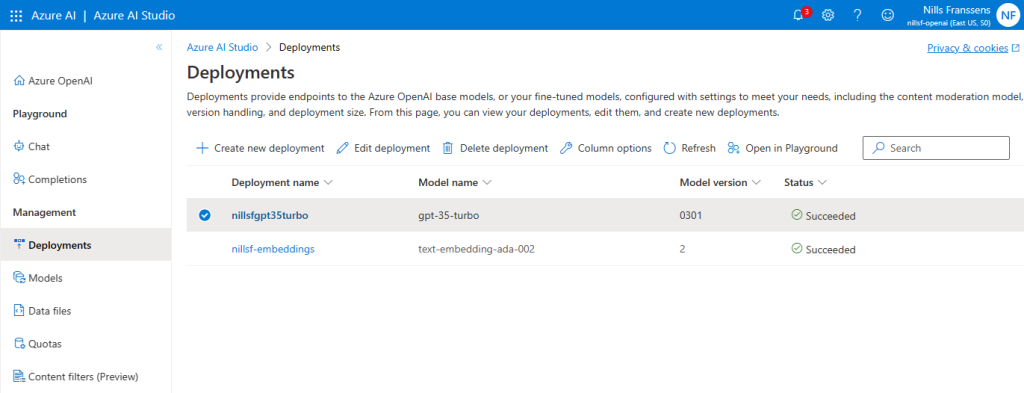
Next, you’ll want to head over to the OpenAI studio to get the deployment information. Please take care of noting the differences between the deployment name and the model name – in case they’re different.
How to load the settings file using dotenv
It’s common in most LangChain examples I’ve seen to leverage dotenv to load environment variables. Let’s follow that practice here as well.
Save the file you created earlier (repeated below) with your OpenAI config information as a file called .env. In your Python code, you can then load those variables as environment variables using dotenv.load_dotenv().
OPENAI_API_BASE = "https://nillsf-openai.openai.azure.com/"
OPENAI_API_KEY = "xxx"
OPENAI_API_TYPE = "azure"
OPENAI_DEPLOYMENT_NAME = "nillsf-embeddings"
OPENAI_DEPLOYMENT_VERSION = "2"
OPENAI_MODEL_NAME="text-embedding-ada-002"How to connect LangChain to Azure OpenAI
There’s a couple of OpenAI models available in LangChain. In what follows, we’ll cover two examples, which I hope is enough to get you started and pointed in the right direction:
- Embeddings
- GPT-3.5-turbo (chat)
Each works very similarly in Azure OpenAI setup, and each has a couple of ways to configure the Azure endpoint. Let’s cover them:
Embeddings
By only pointing to the deployment name
If you followed the instructions up to this point and specified the .env file mentioned earlier – you only need to specify the deployment_name in the OpenAIEmbeddings rather than the model name you’d use if you were OpenAI in the non-Azure version:
import os
from langchain.embeddings import OpenAIEmbeddings
import dotenv
# Load environment variables from .env file
dotenv.load_dotenv()
# Create an instance of the OpenAIEmbeddings class using Azure OpenAI
embeddings = OpenAIEmbeddings(
deployment=os.getenv("OPENAI_DEPLOYMENT_NAME"),
chunk_size=1)
# Testing embeddings
txt = "This is how you configure it directly in the constructor."
# Embed a single document
e = embeddings.embed_query(txt)
print(len(e)) # should be 1536Constructor method
If for any reason you either don’t feel like using the .env file or want to more specifically control the environment you use, you can do that as well. For the LangChain OpenAI embeddings models, it’s possible to specify all the Azure endpoints in the constructor of the model in Python:
embeddings = OpenAIEmbeddings(
openai_api_type="azure",
openai_api_key=os.getenv("OPENAI_API_KEY"),
openai_api_base=os.getenv("OPENAI_API_BASE"),
deployment=os.getenv("OPENAI_DEPLOYMENT_NAME"),
model=os.getenv("OPENAI_MODEL_NAME"),
chunk_size=1)In this case, I’m still getting the variables from the .env file (os.getenv() method) — but you could also go ahead and configure those any other way.
Side note: Don’t bother importing and configuring openai package
Another approach I’ve seen is to import and configure the openai package in Python, rather than deal with the environment variables. Some code samples online, follow this approach that doesn’t work:
# This does nothing for OpenAIEmbeddings()
import openai
openai.api_type="azure"
openai.api_key="xxx"
openai.api_base="https://nillsf-openai.openai.azure.com/"
openai.api_version = "2023-05-15"Chat aka gpt-35-turbo
Chat works a bit different from embeddings. With embeddings, as you might have noticed; you can import the same class (nothing Azure specific about it), but for chat; you need to import a specific class (AzureChatOpenAI ). Let’s have a look.
First, make a small change to your .env file (which I named chat.env for the second set of examples) to reflect the name of the gpt-35-turbo model:
OPENAI_API_BASE = "https://nillsf-openai.openai.azure.com/"
OPENAI_API_KEY = "xxx"
OPENAI_API_TYPE = "azure"
OPENAI_DEPLOYMENT_NAME = "nillsfgpt35turbo"
OPENAI_DEPLOYMENT_VERSION = "0301"
OPENAI_MODEL_NAME="gpt-35-turbo"Let’s now look at how to use this:
Environment variables with deployment name
Pretty similar to the previous example actually, we load the environment variables and pass the deployment name of our GPT 3.5 model into the constructor:
import os
import dotenv
from langchain.chat_models import AzureChatOpenAI
from langchain.schema import HumanMessage
# Load environment variables from .env file
dotenv.load_dotenv(dotenv_path='./chat.env')
# Create an instance of the AzureChatOpenAI class using Azure OpenAI
llm = AzureChatOpenAI(
deployment_name=os.getenv("OPENAI_DEPLOYMENT_NAME"),
temperature=0.7,
openai_api_version="2023-05-15")
# Testing chat llm
res = llm([HumanMessage(content="Tell me a joke about a penguin sitting on a fridge.")])
print(res)
Constructor method
Again, similar to the previous example with embeddings; you can be more specific with your models or endpoints in case you want to:
llm = AzureChatOpenAI(
openai_api_type="azure",
openai_api_key=os.getenv("OPENAI_API_KEY"),
openai_api_base=os.getenv("OPENAI_API_BASE"),
deployment_name=os.getenv("OPENAI_DEPLOYMENT_NAME"),
model=os.getenv("OPENAI_MODEL_NAME"),
temperature=0.7,
openai_api_version="2023-05-15")Conclusion
That’s it! You now have the necessary information to connect LangChain to Azure OpenAI for both embeddings and the chat model (GPT-3.5-turbo).
Feel free to explore further and customize the integration according to your specific needs. LangChain provides a powerful framework for leveraging language models and allows you to build fully featured AI apps.
Remember to refer to the official documentation of LangChain and Azure OpenAI for more detailed guidance and additional features.